-
[선형회귀분석+ 산점도/선형회귀그래프] 환경에따른주택가격예측하기DataAnalysis/모델 분석 2022. 6. 1. 01:01
<개념 설명>
1. 회귀분석: 입력 데이터를 기반으로 결과를 예측하는 것
2. 머신러닝
-1959년 아서 사무엘: ‘컴퓨터에 명시적인 프로그램 없이 스스로 학습 할 수 있는 능력을 부여하는 연구분야’로정의
–인간이 지식과 경험을 학습하는 방법을 용하여 컴퓨터에 입력된 데이터에서 스스로 패턴을 찾아 학습하여 새로운 지식을만들고 예측하는 통찰을 제공하는 AI의 한 분야
3. 머신러닝 프로세스
–데이터수집→ 데이터 전처리 및 훈련/테스트 데이터 분할→ 모델구축및학습→ 모델평가→ 예측
4. 지도 학습
-학습을 하기 위한 훈련 데이터에 입력과 출력을 같이 제공
-문제에 대한 답을 아는 상태에서 학습하느 방식
-입력: 예측 변수, 속성,특징
-출력: 반응 변수, 목표 변수,클래스,레이블
5.사이킷런
-마지막 컬럼 종속 변수 Y, 데이터셋 객체의 target배열로 관리
-전체 n개의 컬럼 중 아으로 (n-1)개의 컬럼은 독립 변수 x
6. 분석 평가 지표
-회귀 분석 결과에 대한 평가지표: 예측값과 실제값의 차이인 오류의 크기

<프로젝트>
프로젝트 설명: 보스턴 주택 가격 데이터에 머신러닝 기반의 회귀 분석을 수행하여 주택 가격에 영향을 미치는 변수를 확인하고 그 값에 따른 주택 가격을 예측하는 것
-주택에 관련된 변수 독립변수 x
-주택 가격 종속 변수 y
데이터 가져오기
import numpy as np import pandas as pd from sklearn.datasets import load_boston boston= load_boston() print(boston.DESCR) boston_df= pd.DataFrame(boston.data, columns = boston.feature_names) boston_df.head() boston_df['PRICE'] = boston.target print('보스톤주택가격데이터셋크기: ', boston_df.shape)
선형회귀분석 모델생성 및 훈련from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score #X, Y 분할하기 Y = boston_df['PRICE'] X = boston_df.drop(['PRICE'], axis = 1, inplace= False) #훈련용데이터와평가용데이터분할하기 X_train, X_test, Y_train, Y_test= train_test_split(X, Y, test_size= 0.3, random_state= 156) #선형회귀분석: 모델생성 lr= LinearRegression() #선형회귀분석: 모델훈련 lr.fit(X_train, Y_train) #선형회귀분석: 평가데이터에대한예측수행-> 예측결과Y_predict구하기 Y_predict= lr.predict(X_test) mse= mean_squared_error(Y_test, Y_predict) rmse= np.sqrt(mse) print('MSE : {0:.3f}, RMSE : {1:.3f}'.format(mse, rmse)) #평가지표 R2를 구함 print('R^2(Variance score) : {0:.3f}'.format(r2_score(Y_test, Y_predict))) print('Y 절편값: ', lr.intercept_) print('회귀계수값: ', np.round(lr.coef_, 1))#회귀계수값과, X.COLUMNS 피처이름을 묶어서 SERIES coef= pd.Series(data = np.round(lr.coef_, 2), index = X.columns) coef.sort_values(ascending = False)
차트그리기import matplotlib.pyplot as plt import seaborn as sns fig, axs = plt.subplots(figsize = (16, 16), ncols = 3, nrows = 5) x_features = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'] for i, feature in enumerate(x_features): row = int(i/3) col = i%3 sns.regplot(x = feature, y = 'PRICE', data = boston_df, ax = axs[row][col])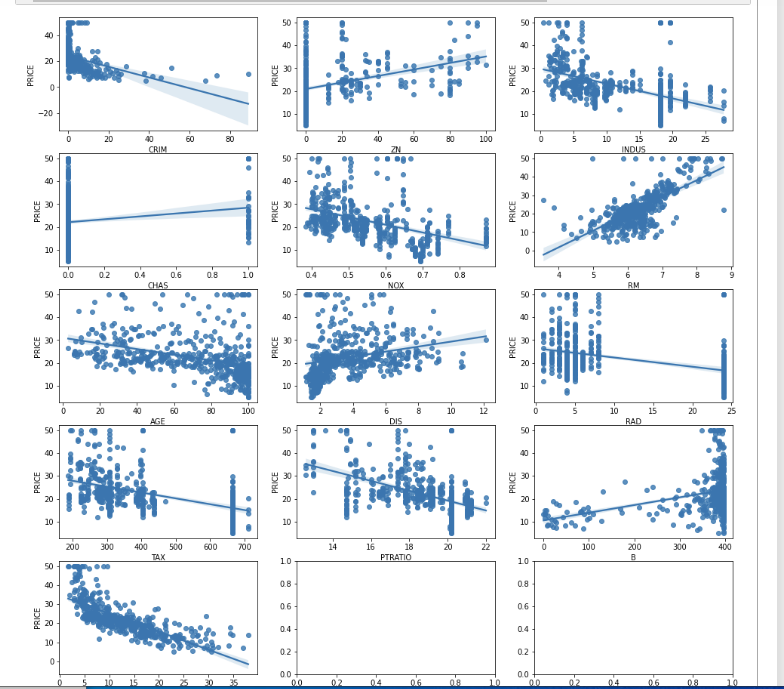
출처: 데이터 과학 기반의 파이썬 빅데이터 분석(이지은 지음)책을 공부하며 작성한 내용입니다.
'DataAnalysis > 모델 분석' 카테고리의 다른 글
[결정 트리 분석] 센서 데이터로 움직임 분류하기 (0) 2022.06.02 [로지스틱 회귀 분석] 특징데이터로 유방암 진단하기 (0) 2022.06.01 [선형 회귀] 자동차 예상 연비 예측하기 (0) 2022.06.01 [상관분석+히트맵] 타이타닉호 생존율 분석하기 (0) 2022.06.01 [기술통계분석] 와인 품질 예측하기 (0) 2022.06.01